13 de outubro de 2023
De Relacional a NoSQL e por quê?
Em algum momento de sua trajetória profissional como programador, analista ou engenheiro de software, você já deve ter se deparado com a seguinte pergunta

Em algum momento de sua trajetória profissional como programador, analista ou engenheiro de software, você já deve ter se deparado com a seguinte pergunta:
Quais são os cenários ideais para o uso de bancos de dados relacionais e bancos de dados NoSQL (não relacionais)?
Pois bem, a resposta que por muito anos eu usava era algo assim: “Opto por um banco relacional quando tenho dados bem estruturados (schemas bem definidos) e quando não, opto por um NoSQL”.
Pois bem, a resposta não é de se jogar totalmente fora, mas ela pode e deve ser melhor elaborada e entendida, espero poder enriquecer de alguma forma essa discussão com esse artigo.
Porque o termo NoSQL?
Para os curiosos de plantão, o termo NoSQL tem origem de um nome dado à uma reunião realizada nos Estados Unidos entre desenvolvedores que tinham o intuito de fomentar e entender melhor sobre o assunto do momento que ocorria em meados de 2009, que era sobre esses novos bancos de dados que estavam surgindo.
Embora os bancos de dados NoSQL não utilizam a linguagem SQL, o nome não possui uma ligação direta com essa característica, por mais que existem bancos NoSQL que possuem a linguagem de consulta parecida.
Outro ponto interessante, é que o termo NoSQL não possui uma definição genérica, o que podemos fazer é analisar as característica comuns entre os bancos que estão de baixo dessa termo (guarda-chuva), assim por dizer.
Mas por que mexer em time que esta ganhando?
Com a web no século XXI, o mundo está conectado a todo tempo, consequentemente grandes volumes de informações e dados são gerados constantemente. Diante desse cenário, surge a necessidade crucial de armazenar esses dados de forma eficaz.
Mas por que não armazenar esses dados em bancos já existentes, como os bancos relacionais?
O que mais chama a atenção no NoSQL é sua capacidade de executar banco de dados em um grande cluster. Conforme os volumes de dados aumentam, o trabalho de de fazer uma expansão em bancos relacionais se torna mais difícil e caro, uma vez que existe a necessidade de compra de um novo servidor maior do que o banco relacional está (escalonamento vertical).
Uma opção que se torna interessante é a escalonamento horizontal, uma forma distribuída dos dados, isso se torna possível com os bancos sendo executados em um cluster que possui um pool (uma quantidade) de nodos, vale salientar que essa decisão introduz um malefício para as equipes: a complexidade.
De forma resumida existe duas maneiras para a distribuição dos dados no cluster: a replicação e fragmentação. Nós não iremos entrar em detalhes, mas em termos gerais a replicação copia o mesmo dados em diversos nodos, já a fragmentação coloca os dados diferentes em nodos diferentes. Não necessariamente você terá que escolher entre as duas, você pode utiliza ambas.
Outro fato interessante para termos mais razões para se considerar o uso do NoSQL, é a necessidade das equipes de entregas serem constantemente provocadas em termos de eficiência (no planejamento, desenvolvimento) de projetos, para assim, o grande objetivo de “time to market” das empresas serem atingidos. Sabemos que planejar e realizar o mapeamento de dados (schemas) é um processo custoso e os bancos NoSQL possam ser uma opção nessa provocação.
Algumas principais características que podemos destacar dos bancos NoSQL são:
- Boa execução em clusters;
- Não possuem schemas;
- Não utilizam o modelo relacional;
- São open-sources.
Precisamos destacar também o termo persistência poliglota, que nada mais é que agora há diversas opções para o armazenamento de dados, com isso precisamos entender os dados que estamos trabalhando e o problema em questão e tentar realizar a melhor escolha dado as opções de banco de dados que agora temos disponíveis.
Vamos entender um pouco melhor as categorias dos bancos NoSQL existentes.
Bancos de dados de chave-valor
São bancos que armazenam seus dados em um tabela de hash simples, o que é isso? São tabelas que você armazena os dados em formas de pares de chave e valor. Aqui temos o conceito de deposito de chave-valor, que nada mais são do que os depósitos de dados NoSQL mais simples de utilizar, possibilitando as funções de inserir, atualizar, excluir e pesquisar, a partir de uma chave informada.
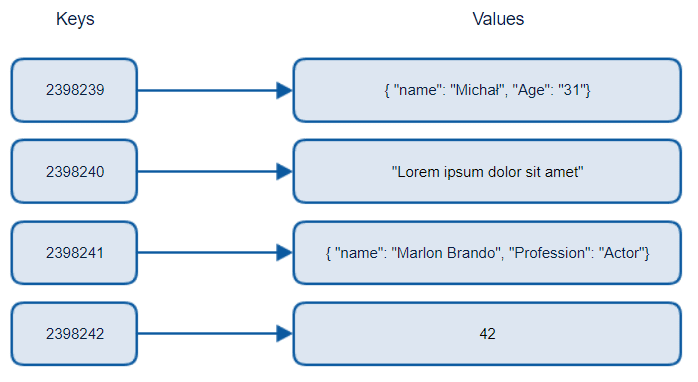
São indicados para armazenamento e recuperação rapidos de dados com operações simples de leitura e escrita. Ideais para armazenamentos temporários de dados tornando super indicado para sessões, cache, carrinho de compras de usuário, por exemplo.
Não são muito indicados quando há a necessidade de consultas mais complexas e modelagens de dados mais estruturados que possuem um grande relacionamento entre si.
Exemplos de banco: Redis, MemCachedDB, DynamoDB.
Bancos de dados colunares
Permitem o armazenamento dos dados com chaves mapeadas para valores, os valores são agrupados em múltiplas famílias de colunas.
Famílias de colunas são grupos de dados relacionados que na maioria dos casos são acessados juntos.
Cada família de coluna pode ser comparada a um contêiner, conjunto de linhas em uma tabela SQL, onde a chave identifica a linha, que é constituída de múltiplas colunas. A diferença que a linha não precisa ter as mesmas colunas, onde uma nova coluna pode ser adicionada facilmente a qualquer linha ser ter a necessidade de ser adicionada em todas.
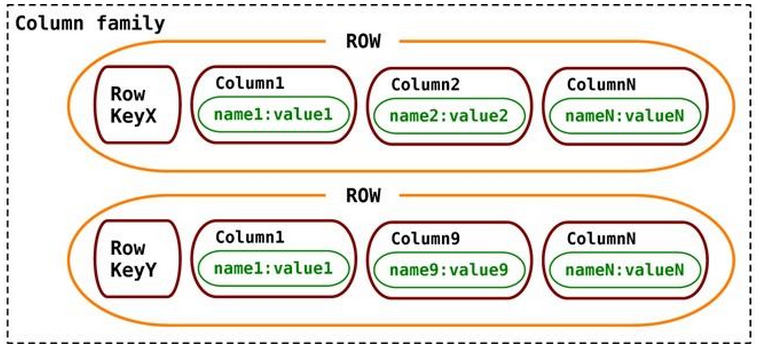
Devido sua alta eficiência em compressão de dados e otimização para consultas, normalmente são indicados e usados em registros de eventos, como logs, devido o grande volume de dados que são gerados e armazenados e por muitas vezes há a necessidade de consultas analíticas complexas.
Por outro lado, quando o acesso rápido a um único dado for necessario ou existir uma estrutura de dados altamente relacionadas, os bancos de dados colunares não são muito indicados devido não serem otimizados para essas operações.
Exemplos de banco: Cassandra, HBase, Google BigQuery, Azure SQL Data Warehouse.
Bancos de dados de grafos
São bancos que armazenam entidades, possibilitando também o relacionamento entre elas.
Entidades são conhecidas como nodos que por sua vez possuem uma ou mais propriedades.
Os relacionamentos são conhecidos como arestas que também podem ter propriedades. As arestas possuem significância direcional, o que isso significa? Que elas possuem uma relação unidirecional, uma direnção definida de um nodo de origem para um nodo de destino.
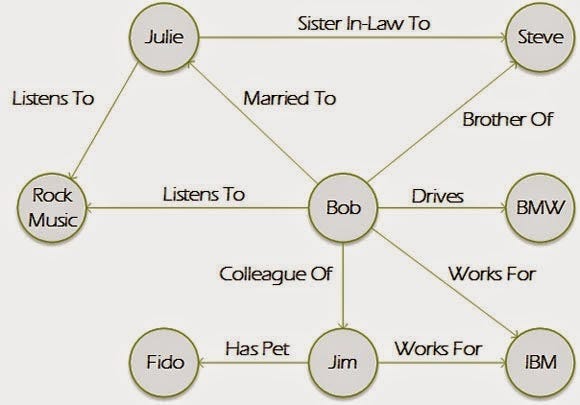
Com essas características e fácil relacionamento entre os nodos atraves das arestas, esse tipo de banco é bastante usado e indicado quando os dados possuem relacionamentos complexos e interconectados, conseguimos fazer uma conexão com as redes sociais ou sistemas de recomendações onde todos os dados são interconectados.
Já essa caterogia não é muito recomendada quando não há a necessidade de exploxar esses relacionamentos, e quando há necessidade de consultas simples principalmente com um único dado.
Exemplos de banco: Neo4J, Amazon Neptune.
Banco de dados de documentos
São bancos que armazenam e recuperam documentos que são semelhantes entre si, mas não necessariamente idênticos, na maioria dos casos os documentos são XML e JSON.
Pense no armazenamento de chave-valor, os documentos são armazenados na parte do valor e esse valor pode ser examinado (queries).
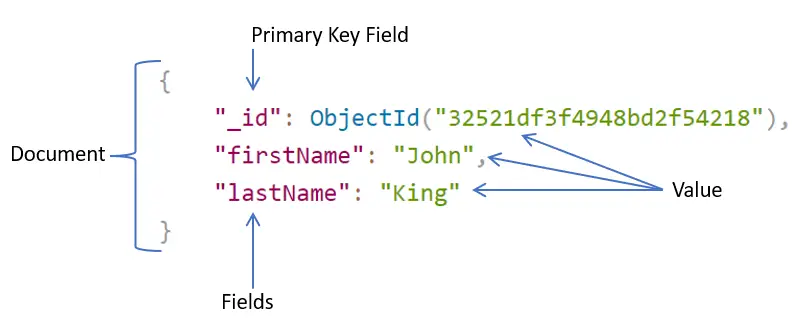
Um característica é no valor do documento, não há atributos vazios, nulos. Também os documentos permitem que sejam adicionados novos atributos e que não tenha a necessidade de mapear o novo atributo nos documentos já existentes.
Essa categoria de banco é fortemente indicada quando a necessidade de um esquema flexível, uma vez que você pode adicionar novos documentos com atributos diferentes sem ter que alterar os já existentes.
Já quando os dados são fortemente tipados, altamente relacionados, o acesso rápido seja um requisito, consultas complexas serão frequentes e a consistência rígida que garanta que todas as réplicas de dados estarão atualizadas, essa categoria não é a mais indica.
Exemplos de banco: MongoDB, CouchDB, Firebase Firestore.
Temos diversos assuntos a serem explorados quando falamos dos bancos NoSQL, como os modelos de distribuição, consistências (Teorema CAP), marcadores de versões, mas a minha intenção principal era dar um panorama geral das categorias existentes de bancos não relacionais e enriquecer um pouco mais a resposta que poderia ser dada para a primeira pergunta desse artigo.
Tenham em mente que, nenhuma das tecnologias hoje existente é dada como uma bala de prata. Essa regra serve para os bancos NoSQL também. Com isso é essencial o time de engenharia testar, validar suas expectativas sobre a produtividade, desempenho do time antes de decidir utilizar um desses bancos.
Publicado originalmente no Medium.